tldr: We’re want to let machines run industrial bio processes/operations on their own (dose the wash water, dump the bad batch, ship or hold a batch, etc) but to trust such an autonomous system, we’ll have to grade it, just like robotics and self-driving cars are. A system in this sense is just a loop i.e. see - decide - act - repeat. For robots the weak link in this loop is deciding. For a bioprocess it’s basically seeing, right now. The thing we care about (how much live bio is in here, now) is invisible, slow to measure, and you can’t rewind to check (label). So before we benchmark the decisions, we have to benchmark the seeing.
There’s a lot of excitement about putting AI in charge of physical things in bio. This post is a basic question : if a system ran your process by itself, how would you even know it was any good? The binary answers for good or bad are easier (operational outputs, financial statements, etc), but that does nothing to help build or refine these systems in the first place.
So, it’s a benchmarking question. Self-driving and robotics have been already been doing this, and this post creates one for industrial bio.
Thanks for reading Digvijay's Substack! Subscribe for free to receive new posts and support my work.
The loop
Fundamentally, any machine system that acts in the world is an OODA loop. It senses. It guesses what’s going on. It decides. It acts. The world changes, and it senses again. A hundred times a second, or a few times an hour.
A loop is only as good as its weakest link. A great decision on a blind sensing is a blind guess. In robotics, a perfect actuator aimed wrong hits the wrong thing, precisely. So the question “is this thing any good?” is really: does it see (O), does it know where it is (O), does it choose well (D), does the action land (A).
I started looking into robotics and selfdriving to understand this. imo, most benchmarks are built around weak links in the OODA loop.
In robotics, the cameras are fine, the hard part is the orientation and decision making. So they graded tasks like can it fold the towel.
Interestingly, the scores hit highs very quickly but it turned out the models had memorized the test, and different conditions such as lighting really affected performance. So the fixed task tests were replaced with ranking robots head-to-head in the real, messy world a la Roboarena.
Now point this at a wash tank.
Bio’s weak link is sensing
For a packhouse, the system needs to understand how much live, dangerous organisms are in here right now. Three things are true about this case which aren’t true for a car.
It’s invisible. You can be carrying something that floors you next week and feel fine today, completely unseen. You can’t point an instrument at the water and read “pathogen load” the way a camera reads a stop sign.
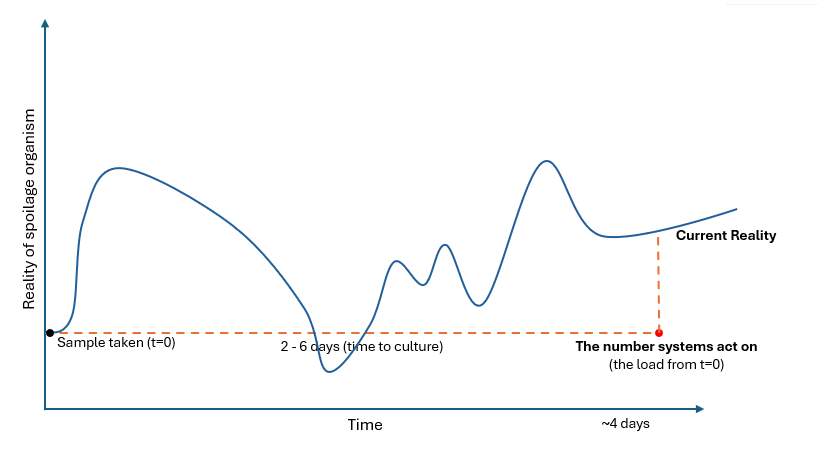
The only way to see it is slow. To get a number you take a piece of the world and grow it. That takes days. Think of a shower with a 20-second delay: you nudge it hot, nothing, you nudge again, then it scalds, so you slam it cold, and now you’re stuck swinging between freezing and burning. Steering on a slow reading feels exactly like that.
Figure: The lab answer is accurate but about a moment that’s days gone. By the time it arrives, the process has moved on.
And you can’t rewind to check. This is the one that separates bio even from self-driving. While training, if you’re unsure what the car saw, you can replay the logs, pull over and look, rebuild it in sim. i.e. recover ground truth by replaying or simulating. But a batch of apples that went through the tank at 9:42 this morning are shipped, eaten, or spoiled; that exact moment is biologically closed, and no instrument invented later can recover it. You can’t replay a living culture or simulate one into existence. The simplest way to recon is to get reports of spoilage or outbreaks and label data that way. Too slow to be useful.
So in a bioprocess the decision is easy (atleast right now). The seeing is the weak link amd no amount of compute fixes it from the outside.
So you benchmark the eye, not the brain
So you want to grade the eye? imo it has to do three things. (Each is a test you can run.)
See the whole system, not one spot. Checking one aisle of a dark warehouse with a flashlight, seeing nothing, and calling the place clear is bad lol. Seeding the tank without mixing and cross checking loads measured by system.
See it in time. The delayed shower example. Measure the time from event to a number you can act on, including the days the biology needs just to become detectable. Accurate but late is useless.
Mean the same thing twice. Two thermometers both reading 70, one in the sun, one in a shade. Test whether two sites reporting the same number mean the same physical thing. If they don’t, you can never pool their data.
(That last one is where the dream of a “foundation model for bio” quietly lives or dies. You can’t build one on numbers that don’t mean the same thing across facilities. Comparable measurement is the thing that makes the data exist.)
Only after the eye passes does grading the brain, the decision making mean anything. And there we can just copy robotics protocols.
You can’t automate faster than you can see
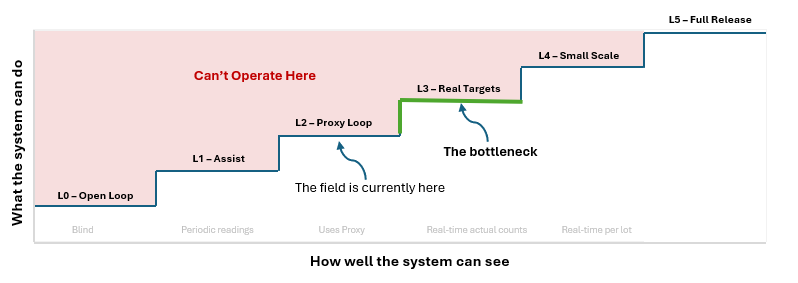
This also tells you how far you’re allowed to go. Nobody lets a car drive itself faster than its sensors can see. In foggy days, we/it slows down. Autonomy is capped by perception. Saw this fun diagram here so redrawing it for our discussion:
Adapting this for our industrial bio autonomy discussion:
Figure: You’re only safe below the steps, where what the machine can do and how well it can see rise together. The red zone above is more autonomy than the seeing supports. Most of industrial bio sits at the L2 wall. To cross it, we have to fundamentally redo sensing.
x axis: how well it can see (the seeing is the thing everything else rests on) ; y axis : how much the machine may do.
Two things:
Autonomy is obviously capped by the eye, not the brain (the can’t operate here region).
There’s a wall between L2 and L3. Below it you steer on a proxy essentially. Chlorine standing in for pathogen load is like judging stadium attendance by how loud it is. You can hold the proxy perfectly while it stops tracking the real thing (a half-empty crowd can still roar). Crossing the wall means steering on a real number, and that’s impossible without rebuilding how you see in bio.
Industrial bio is L0 to L2 now. Sanitizers run on a timer. Products is routed on a schedule. Shelf life is guessed from cold chain temperature (a proxy for spoilage).
Some stuff does exist, some doesn’t
Process control’s “levels” (ISA-95, etc) level the control hierarchy (sensing, control, MES, ERP), not autonomy. Genuine autonomy scales also do exist: a six-level “autonomous plant” proposal modeled on the driving levels, manufacturing autonomy-maturity models, pharma’s PAT, etc.
But every one grades the controller and assumes the measurement underneath is sound. None gates the level on whether you can actually see — bolting a seeing gate onto each doing level, so bad measurement caps autonomy by rule is the thing. If we want to build some sort of foundational model for industrial bio by training on a group of sites, defining the data collected matters a lot. Atleast our goal for a model is to bring new facilities online on day 1, without having to collect a huge chunk of facility data first.
Here’s a GPT generated document of what a standard should look like :
If the leverage is the eye, build the eye. That’s what we’re doing at Drizzle. MagnaFlow tries to pass all three tests at once: take the whole batch of wash water as the sample, not a grab from one spot (whole system); get a signal in minutes, no days-long culture (in time); tie it to that specific lot, the same way every time (means the same thing twice).
—
Digvijay Singh is co-founder of Drizzle Health. Drizzle builds sampling, concentration & testing solutions for bio testing across lab and industrial scales.
Thanks for reading Digvijay's Substack! Subscribe for free to receive new posts and support my work.




{kind=link}